透過 Selenium 與 BeautifulSoup 進行爬蟲工作
網頁的自動化測試常提到 selenium ,
除了測試以外,
也可透過 selenium 來進行爬蟲工作,
Selenium支援許多瀏覽器,
幫助程式在網站進行各種自動化操作,
今天就來教大家:
透過 selenium 與 BeautifulSoup 進行爬蟲工作
第一個步驟當然是宣告需要的套件:
from bs4 import BeautifulSoup
from selenium import webdriver
import time
如果是使用 Selenium 打開瀏覽器的話,
需要先到此處下載 chrome driver
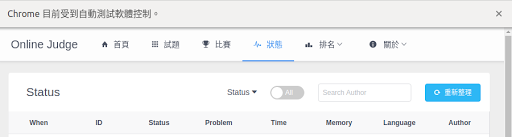
程式開啟的視窗會顯示目前受到自動測試軟體控制,
driver = webdriver.Chrome("chrome driver的路徑")
driver.get("要測試的網址")
time.sleep(2) # 必須等待資料 ready,視情況修改等待秒數
html = driver.page_source
driver.close() # 關閉瀏覽器
soup = BeautifulSoup(html, "html.parser")
至此,
其實已經擷取到目標網頁的所有資料,
透過 selenium 或者 BeautifulSoup 提供的方法可以找到需要的資料,
例如:
tag_li = soup.find(attrs={"class": "ivu-table-body"})
tag_span = tag_li.find_all(["span", "a"])
for x in tag_span :
print(x.string)
tag_li 是為了找到 class name 為 ivu-table-body 的所有資料,tag_span 則找出在 ivu-table-body class中 html 標籤為 span 與 a 的資料最後再將這些資料全部印出
若處理多個網頁會看到 selenium 一直開關瀏覽器,
要解決此問題有兩種方法:
- 透過參數讓瀏覽器在背景執行
options = webdriver.ChromeOptions()
options.add_argument(‘–headless’)
browser = webdriver.Chrome(chrome_options=options,executable_path=’chrome driver的路徑’)
browser.get(要測試的網址)
- 使用 pyvirtualdisplay 與 Xvfb 來虛擬顯示器
from pyvirtualdisplay import Display
display = Display(visible=0, size=(800, 600))
display.start()
#加入要執行的程式碼
display.stop()

若是看到如上圖的錯誤訊息,
並非程式出錯,
而是沒有安裝 xvfb :
sudo apt-get install xvfb
為何已經使用 BeautifulSoup 還要透過 selenium?
原因很簡單,
由於某些資料經過 js 才能顯示,
但使用 requesets 不能保證取得需要的資料,
透過 selenium 才能真正產生資料
================================
分享與讚美,是我們繼續打拼的原動力.
若文章對您有幫助,望請不吝按讚或分享.
或者對影片有興趣可以訂閱頻道接收通知
================================
YouTube 頻道
FB 粉絲專頁
================================


